Key Takeaways
Most cloud breaches occur due to misconfigurations and excessive permissions rather than advanced attacks.
At scale, cloud environments change faster than governance processes can keep up.
Cloud security resilience depends on a continuous cycle of detection, prioritization, and remediation.
Identity and access management form the core control layer for reducing cloud risk.
Policy-as-code helps prevent misconfigurations by enforcing security before deployment.
Automation is essential to handle large volumes of findings and ensure timely remediation.
Real-time compliance enables organizations to maintain continuous audit readiness instead of relying on periodic reviews.
Here is what cloud security actually looks like inside most organizations right now: tools deployed, policies written, a team that genuinely cares, and a posture that still erodes every quarter. Not because of zero-days. Because the environment is growing faster than the governance keeping up with it. Cloud security posture resilience is the answer to that problem, and building it at scale requires a different operating model than what works for ten accounts.
Resilience here means something specific: the continuous ability to detect misconfigurations and identity risks when they appear, prioritize them by real-world impact rather than theoretical severity, remediate them within defined timelines, and adapt when the environment changes around you. It is a loop, not a project. This guide covers how to build that loop and keep it running as cloud environments grow.
What Actually Breaks as Cloud Environments Scale
Most post-mortems on cloud security incidents tell a surprisingly boring story. It was not a sophisticated attack or an unknown vulnerability. It was a storage bucket someone set to public four months ago, or a service account with admin rights left over from a migration that ended six months back. The Cloud Security Alliance ranked misconfiguration and inadequate change control as the single largest cloud threat in its 2024 Top Threats report, above ransomware. Gartner puts 99% of cloud security failures on the customer, driven by configuration errors and poor access governance.
What makes this hard at scale is velocity. Small teams running ten cloud accounts can, in theory, manually review configurations and catch most of this. The moment you cross into dozens of accounts with multiple engineering teams pushing infrastructure changes daily, the math stops working. A developer changes a security group rule. An automated deployment skips an encryption tag. A temporary role persists because nobody thinks to revoke it after a project closes. Each one is small. Together, across a large environment, they create a posture that has more exposure than anyone realizes.
IBM found that 87% of organizations run workloads across multiple cloud providers. AWS, Microsoft Azure, and Google Cloud Platform all use different IAM models, different configuration terminology, and different defaults. Without a centralized governance layer, there is no realistic way to enforce consistent security controls across those environments. And inconsistency is where attackers find their footholds.
“All cloud security failures are identity failures, and all identity failures are governance failures.”
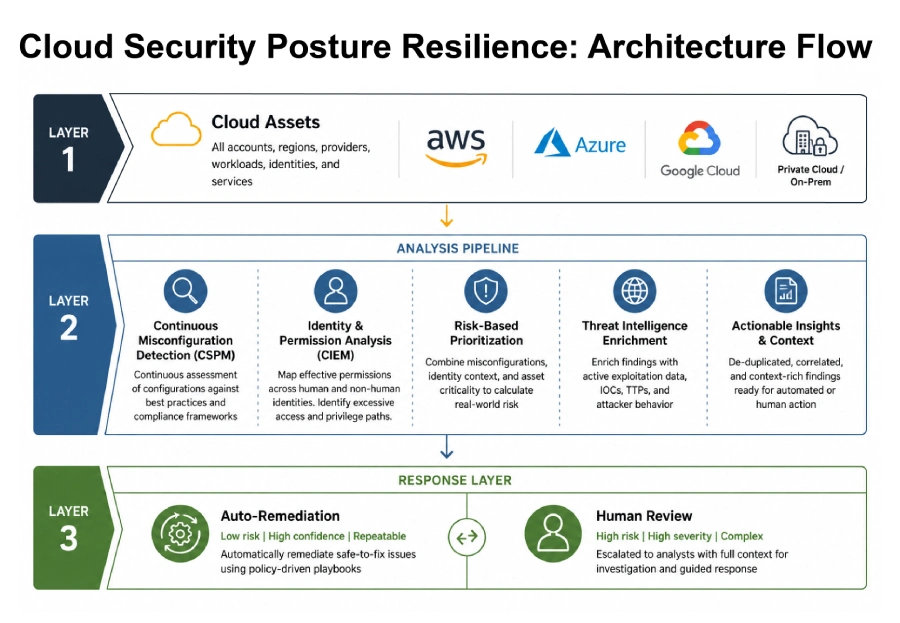
The Architecture: How the Pipeline Actually Works
Cloud security posture resilience is a detection and response pipeline, not a product you deploy once. Understanding how the stages connect makes it clear why each layer exists and what breaks if one is missing.
Each stage filters what reaches the next. A large cloud environment might generate thousands of raw findings daily. After risk prioritization and threat intelligence enrichment, maybe 15 to 20 need a human today. The rest are auto-remediated or queued with SLA timelines. That filtering is what makes the resilience loop scalable. Without it, security teams are triaging everything manually, which is exactly how critical findings end up buried and unaddressed for months.
The five capability layers feeding the pipeline:
Foundation
Centralized Visibility
Unified inventory across AWS, Azure, GCP, and private cloud with continuous asset discovery. Every account, every region, every resource type visible from one place.
Control
Identity and Entitlement Management
CIEM maps what every identity can actually do across cloud environments, surfacing the gap between stated IAM policy and effective permissions across inheritance chains and cross-account trusts.
Compliance
Continuous Compliance Monitoring
Real-time deviation alerts against GDPR, HIPAA, PCI DSS, SOC 2, and NIST CSF 2.0. Drift detected in minutes, not discovered in the weeks before an audit.
Protection
Cloud Workload Protection
CWPP defends running containers, VMs, and serverless functions at runtime. CSPM catches configuration problems at deployment. CWPP catches active threats that appear after.
Intelligence
Threat Intelligence Integration
Findings enriched with active exploitation data. A misconfiguration enabling a known attack technique surfaces at the top of the queue, not buried in a list of theoretical risks.
Three Operating Model Changes That Make Posture Scalable
The tools above are available to almost every enterprise. What separates organizations with genuinely resilient cloud security posture from those still struggling is not the tooling. It is the operating model. Three shifts are required when you go from a handful of cloud accounts to a large, multi-team environment.
The Modern XDR Playbook with
Fidelis
Early Detection
Response Acceleration
Industry Benchmarks
Federated Ownership With Centralized Governance
A central security team reviewing every cloud configuration change across 50 engineering teams is not a security program. It is a bottleneck. The model that actually works at scale puts the security team in charge of setting policy, running the tooling, and reviewing findings that require judgment. Remediation ownership sits with the teams that own each cloud environment. When a CSPM finding appears in a payment processing account, it routes to the team responsible for that account with a defined SLA, not into a shared queue where accountability evaporates.
This requires your CSPM tooling to support organizational hierarchies and account tagging. It also requires those teams to have explicit SLAs: critical findings addressed within 24 hours, high-severity within 72. Without defined timelines, federated ownership just becomes diffuse ownership, and the posture degrades exactly as it would if nobody owned anything.
Policy-as-Code in CI/CD Pipelines
Catching misconfigurations after they deploy is reactive. Catching them before they deploy changes the resilience equation entirely. Policy-as-code embeds your organization’s cloud security standards into every CI/CD pipeline. When a developer writes Terraform or CloudFormation, the pipeline checks it against policy before anything reaches any environment. Violations fail the build. The misconfiguration never exists in production.
This also solves the compliance drift problem in a way that continuous scanning alone cannot. A policy encoded in the pipeline is enforced on every change, not just checked after the fact. Compliance coverage improves because the drift rate drops, not because security teams are working faster to remediate after the fact.
Tiered Automation Thresholds
At scale, sustainability requires that most findings are handled without human review. The goal is a tiered response model: approximately 70 to 80 percent of findings resolved through automated remediation, the remainder escalated to analysts with enough context to act without extensive investigation. Getting those thresholds right requires iteration. Start conservative, auto-remediate only the highest-confidence low-risk findings, and expand the automation envelope as experience builds. The alternative, asking analysts to review everything, does not scale past a few hundred accounts.
The Risks That Actually Drive Cloud Breaches
The risks below are not theoretical. They are the patterns consistently observed across real-world cloud incidents, and they directly map to where posture breaks down at scale.
RiskSeverityEvidence
Cloud MisconfigurationsCritical23% of all cloud incidents; avg detection time 180+ days; avg cost ~$3.86M per incidentOver-Permissioned IdentitiesCriticalLeaked credentials were the initial access vector in 65% of analyzed cloud breachesCompliance DriftHigh24% of misconfiguration incidents result in regulatory penalties; GDPR and HIPAA are most frequentMulti-Cloud Visibility GapsHigh69% of organizations report difficulty maintaining consistent controls across cloud providersCloud Workload ThreatsHighCloud-conscious intrusions up 37% year-over-year in 2025
Identity at Scale: The Layer Most Programs Under-Invest In
Research presented at RSAC 2025 found that leaked credentials were the initial access vector in 65% of analyzed cloud breaches. In most of those cases, the credential itself was not the real problem. The problem was what that credential unlocked: a service account with admin access to three environments, or a developer role with cross-account permissions that nobody scoped down after a migration project wrapped up.
Cloud infrastructure entitlement management maps the difference between what IAM policies say and what identities can actually do. At scale, that gap is substantial. Non-human identities, service accounts, CI/CD tokens, workload identity credentials, often outnumber human users significantly in large cloud environments and get far less attention in access reviews. They also tend to carry broader permissions because nobody wants to break an automated process by tightening a role. CIEM makes that exposure visible and enforces least-privilege systematically rather than relying on periodic manual reviews that never happen as planned.
Compliance Mandate
NIST SP 800-207 recommends automated entitlement management as a core zero trust component. DORA, in force since January 2025, mandates continuous access monitoring for financial entities. The SEC’s cybersecurity disclosure rules require public companies to document access governance in risk management filings. For regulated industries, CIEM has moved from optional to required.
Compliance at Scale: From Periodic Check to Continuous Signal
The reason compliance fails in large cloud environments is not that teams are not trying. It is that compliance checked periodically cannot keep pace with infrastructure that changes continuously. A configuration compliant on Monday can drift by Wednesday if someone pushes a Terraform change or a cloud provider updates a service default. By the time a quarterly review catches it, the window of exposure has been open for weeks.
Connecting compliance directly to the resilience loop changes this. When every configuration change is assessed against applicable frameworks in real time, compliance becomes a continuous signal rather than a snapshot event. Drift is caught within minutes. The audit-ready dashboard exists because the environment is actually maintained to that standard all the time, not because someone assembled evidence the week before an assessor arrived.
60%
Reduction in audit failures for organizations with real-time compliance scanning vs. those relying on periodic manual reviews.
Frameworks most enterprise cloud environments need to stay continuously aligned with:
PCI DSS for payment data environments, with strict controls around network segmentation and access logging
HIPAA for healthcare workloads, where cloud storage configurations for protected health information are consistently where exposure appears
GDPR for any organization processing EU personal data, with specific data residency and access audit logging requirements
NIST CSF 2.0, recommended by CISA for critical infrastructure and maps directly onto CSPM control categories
CIS Benchmarks for provider-specific hardening across AWS, Azure, and Google Cloud Platform, which are the most technically precise starting point for cloud infrastructure configuration
Maturity Model: Where Is Your Program Right Now?
Cloud security posture resilience develops in stages. Organizations that try to reach Stage 5 immediately without the foundations in place waste both budget and time. Knowing which stage you are at determines what investment actually moves the needle.
Stage 1: Visibility
CSPM connected. You know what exists. Findings reviewed manually. No enforcement yet.
Stage 2: Detection
Real-time alerts on critical misconfigurations. Frameworks mapped. Ownership assigned to findings.
Stage 3: Automation
Policy-as-code in CI/CD. Auto-remediation live. Federated ownership model operational.
Stage 4: Intelligence
Threat intel enriching posture data. CIEM enforcing least-privilege. CWPP covering runtime.
Stage 5: Resilience
Continuous detect-prioritize-recover loop running. KPIs tracked. Program adapts to environment changes.
Most organizations starting this work sit between Stage 1 and 2. They have tooling running but remediation is reactive and manual. Stage 3 is the scalability inflection point: policy-as-code and federated ownership are what allow a security team to maintain posture across hundreds of cloud accounts without headcount growing proportionally. Stages 4 and 5 are about precision and continuity. The resilience loop does not just detect and remediate. It adapts when the threat environment changes, when new cloud services are adopted, and when engineering practices evolve.
First 90 Days: Execution, Not Theory
The 90-day plan works because each phase creates the foundation the next one depends on. Skipping ahead produces gaps that come back as incidents.
Days 1 to 30: Get the Real Inventory
Connect CSPM to every cloud provider account, including accounts provisioned outside of central IT
Run a complete asset discovery scan across all accounts and regions, not the assumed inventory but the actual one
Map every human and non-human identity with cloud access and document their effective permissions
Establish baseline compliance posture before making changes so you can measure improvement
Document which teams own which cloud environments and accounts
Outcome: The gap between your assumed posture and actual posture is visible. The biggest exposures are ranked and owned.
Days 31 to 60: Close the Dangerous Gaps
Close all publicly exposed cloud storage immediately, S3 buckets, Azure Blob containers, GCS buckets
Revoke over-permissioned service accounts and admin credentials not actively tied to a running process
Enable encryption at rest and in transit for every sensitive data store
Enable comprehensive logging across cloud environments for both security monitoring and audit evidence
Set remediation SLAs per severity tier and assign finding ownership to the appropriate teams
Outcome: Highest-severity exposed attack surface closed. Accountability structure established. Critical finding count drops measurably.
Days 61 to 90: Build Prevention and Automation
Implement IaC security scanning in CI/CD pipelines so misconfigurations are blocked before reaching any environment
Configure automated remediation for high-confidence, low-risk finding categories
Deploy cloud workload protection across production workloads for runtime coverage
Implement CIEM controls for least-privilege enforcement and time-limited elevated access
Stand up real-time compliance dashboards across applicable frameworks
Outcome: Prevention is happening upstream. Human review load significantly reduced. The resilience loop is operational, not just planned.
KPIs: Proving the Program Is Working
The resilience loop either improves over time or it does not. These six metrics tell you which one is happening. Track them monthly. Without measurable baselines and trend lines, you are managing a security program on hope.
Target: <30 min
Critical: <24h
Mean time to remediate per severity tier. Track SLA compliance by team, not just organizationally.
Target: >95%
Percentage of cloud resources compliant against applicable frameworks. Track per-framework and per-provider.
Trending Down
Trending Down
Target: >70%
Findings resolved through automated remediation vs. human review. The scaling proof: most findings never need an analyst.
Drift rate and automation coverage together show whether the program is preventing problems upstream. MTTD and MTTR together show whether detection and response are improving. Both trend lines improving simultaneously is what a functioning resilience loop looks like.
Where Fidelis Fits in the Resilience Pipeline
Cloud security posture resilience breaks down when posture data cannot be tied to real-world risk. CSPM and CIEM can surface misconfigurations and identity exposure, but they do not indicate which of those risks are actively exploitable.
Fidelis addresses this gap by combining cloud posture management with runtime and network-level intelligence.
At the core, Fidelis Halo (CNAPP) provides continuous visibility and enforcement across multi-cloud environments. It brings together CSPM, CIEM, and workload protection to:
Continuously detect misconfigurations and compliance drift
Map effective permissions across identities and services
Enforce policy consistently across accounts and environments
Protect workloads at runtime using lightweight agents
This establishes the posture foundation required for resilience at scale, where visibility, enforcement, and drift detection operate continuously rather than as periodic checks.
Fidelis extends this further by adding network and behavioral context, allowing teams to understand which posture risks are actively being leveraged. By analyzing cloud traffic and workload behavior, it surfaces signals such as lateral movement and data exfiltration attempts that posture tools alone cannot detect.
Cloud-friendly Deployment
Hyper-scalable Workload Protection
Agentless Cloud Posture Management
This combination closes a critical gap in the resilience loop:
Posture identifies exposure
Runtime and network intelligence validate active risk
Security teams prioritize based on exploitability, not volume
At scale, this is what enables meaningful prioritization. Without it, teams are left triaging thousands of theoretical risks. With it, the pipeline filters aggressively, and attention is focused where it has immediate impact.
The post A Practical Guide to Building a Resilient Cloud Security Posture at Scale appeared first on Fidelis Security.
No Responses